Continuous Delivery e Migrations não andam juntos
Table of contents
Preparando uma talk interna sobre deployment eu tive memórias da guerra. Memórias de quando trabalhei em uma indústria
de laticínios que possuia todas as suas aplicações em dois servidores bare-metal. Os servidores não eram lá dos
melhores e as tecnologias que usávamos pareciam não escalar corretamente.
Há alguns causos que eu posso contar sobre esse perído da minha carreira. Embora tenha sofrido um pouco nem todo sofrimento é em vão. Eu acredito profundamente que há um tipo de sofrimento que constrói. No geral, isso só pode ser observado ou com experiência ou ligando os pontos, este segundo só acontece depois, então a caminhada pode ser frustrante mesmo.
Um dos momentos mais sofridos e tensos era o deployment de versões. Devido à criticidade da aplicação, fazíamos um processo minucioso e muito cuidadoso para evitar desastres. Nesse post quero compartilhar esse causo e te deixar alguns insights sobre deployment, mais especificamente sobre alteração de banco de dados de produção.
Nossa stack
Nossa stack era tal como descrita abaixo. O core da empresa, e de outras indústrias semelhantes, era o ERP. ERP é um tipo de aplicação que traz consigo muitas funcionalidades que são de extrema importância para os múltiplos setores de uma empresa. Módulos como comercial, logística, estoque, contabilidade e mais.
São muitas atribuições e trabalhar com esse tipo de aplicação te dá uma outra perspectiva.
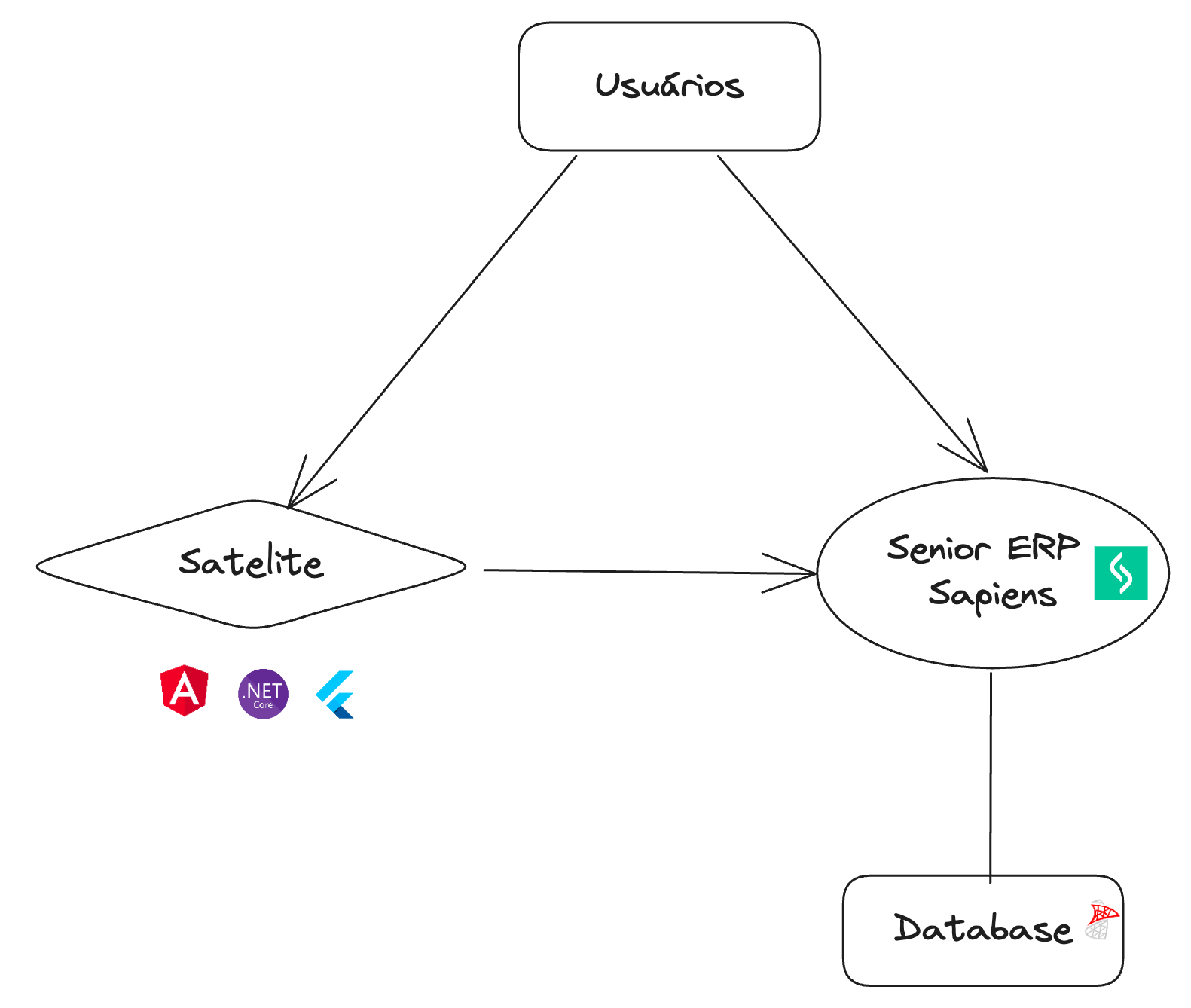
Uma breve descrição:
- ERP Sapiens - Sapiens era o ERP que utilizávamos, fornecido pela empresa Senior Sistemas;
- Satelite - aplicações que ficavam em torno do ERP, aplicações que integravam com ele;
- Banco de dados - Banco de dados SQL Server.
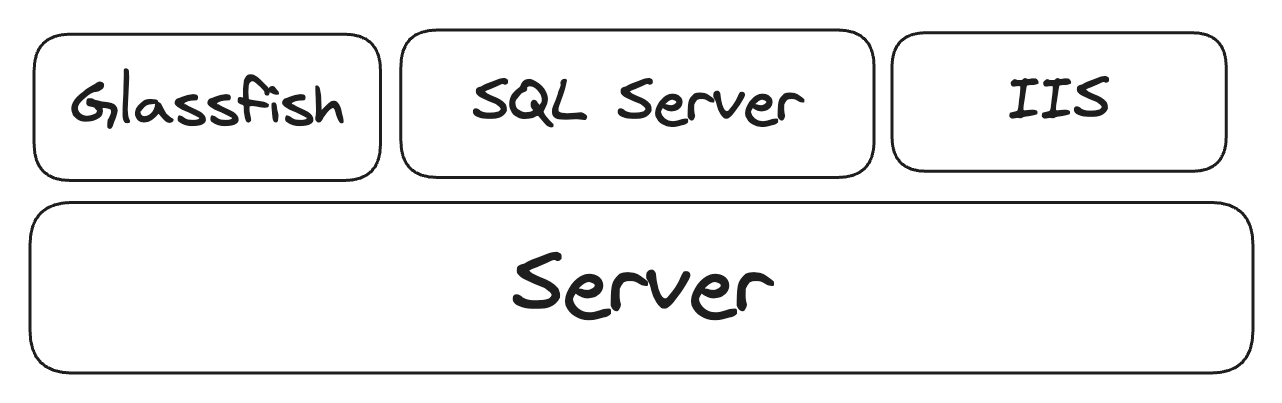
Essa stack rodava em dois servidores: aragorn (teste) e gandalf (produção). Cada servidor tinha Microsoft IIS para execução
das aplicações Satelite, que tinha backand em C# com dotNet e algmas páginas em PHP, tinha Glassfish para execução do
ERP, pois este era escrito em Java, e tinha o banco de dados que, como já mencionado, era SQL Server.
Deployment e Banco de Dados
Agora que você entendeu nossa stack, vamos ao que interessa. As versões eram liberadas pela empresa fornecedora do ERP e era nossa missão fazer a atualização da nossa base de tempos em tempos. E, por incrível que pareça, acredito que tínhamos certas práticas interessantes. Práticas que depois veremos que podem ser utilizadas em suas aplicações.
A cada versão que recebíamos tínhamos uma ideia sobre o que seria modificado, se algo no banco de dados seria invasivo demais etc.
Quase sempre tinha uma mudança de banco de dados sim. Então seguíamos o processo à risca. Que era como segue.
A preparação
O horário comercial da indústria era das 7:30 às 17:30. Em dia de fazer upgrade, notificávamos os setores da empresa acerca disso ainda pela manhã.
Quando o relógio marcava 17:30, iniciávamos nosso rito de deploy que envolvia baixar os programas de upgrade fornecidos pela Senior - fornecedora do ERP que utilizávamos. Depois disso ficávamos por conta do setor de faturamento que fazia emissões de notas fiscais ainda no começo da noite. Ao terminar, aí sim iniciávamos nosso procedimento.
Backup do banco de dados de produção
O primeiro passo era fazer um backup do banco de dados. Isso nos dava a segurança. Se, por algum motivo, o procedimento de atualização falhasse e algo corrompesse poderíamos voltar a este estado.
Teste do backup no servidor de testes
Com esse backup em mãos, fazíamos o restore no servidor de testes e verificávamos se o backup havia sido realizado com êxito.
Upgrage no servidor de testes
Nesse ponto já tínhamos o banco de dados espelhado no ambiente de testes, assim, fazíamos o upgrade na versão de testes primeiro. Nosso objetivo era checar se tudo correria bem para aquele upgrade com aquele estado do banco de dados.
Com esse passo, identificávamos eventuais inconsistências.
Upgrade no servidor de produção
Uma vez que o upgrade funciona como esperado no servidor de testes, partimos, finalmente, para o servidor de produção. Se tudo corresse bem, íamos pra casa. Caso contrário procuraríamos debugar o que houve e, na pior das hipótestes, retomaríamos ao estado anterior do banco de dados, aquele do backup.
Migrations no banco de produção
Diferente do processo descrito na seção anterior, em desenvolvimento web não há um upgrade de um terceiro. O upgrade vem de você mesmo, é seu código. São suas também as mudanças no banco de dados, muitas vezes através de ferramentas interessantes que temos em frameworks, as migrations.
O ponto é que eu não vejo como muito benéfico ter como parte da sua pipeline de deployment pra produção, a execução automática de migrations. Nunca se sabe o que pode acontecer e todo cuidado é pouco.
Acredito que o processo anterior, que fazíamos manualmente, possa ser automatizado como parte de uma pipeline. Mas acho que é imprescíndivel que se tome os mesmos cuidados que tomávamos em tal ambiente rústico. Resumindo, antes de rodar suas migrations em producção:
- faça backup do banco de dados;
- garanta que o backup funcionou;
- tenha a versão funcionando em um outro ambiente que não o de produção - em nosso caso tínhamos dois, mas você pode ter mais;
- execute as migrations para prod.
Notas
- Tenha testes na sua aplicação. São extremamente úteis! Escreva-os.
- Alterações em tabelas grandes podem demorar mais, então certifique-se de notificar seus usuários acerca de uma manutenção programada.
Conclusão
Por hoje é isso. São dicas triviais, mas já vi bastante gente fazendo isso de ter migrations rodando antes do deploy de forma automatizada e a chance de isso dar errado existe e sem backup ficamos com uma aplicação quebrada e uma dor de cabeça enorme.
Por hoje é só. Até a próxima.