Chapter 3
Dealing With I/O Using The ThreadPool
Hello dear contributor. We’re about to touch an exicing part of the implementaion of Node.js and libuv. To leverage this
chapter it’s important that you know how Node event loop works. You don’t not need to have all the order of execution of
setImmediate, setTimeout and process.nextTick. A knowledge about the architectural foundations is good enough.
Let me highlight the needed concepts for you.
Recap Node.js Event Loop
An envent loop works the same way as we when we go to the supermarket. You have your buy list.
You start picking products, you’re focused on them. While picking products from prateleiras you can’t do anything else. That’s like the execution of your JS code.
When the main thread is executing code, it can’t deal with anything else. See the classical example below:
console.log('Hi')
setTimeout(function a() {
while(true);
}, 100);
setTimeout(function b() {
console.log('finish execution')
}, 100);
console.log('How is it going?')
Notice that this code has to be parsed and then executed. All this keeps the main thread busy.
It executes all the four instructions In the following sequence:
- prints
Hi: - schedules function
ato be executed at a given timeout; - schedules function
bto be executed at a given timeout; - prints
How is it going?.
What happens next?
Within at least 100ms the function a will be executed and then boom! Our event loop is blocked!
Remember: The main thread executes JavaScript code and when doing so it can’t do anything else
Our function a is JavaScript code. The main thread will take care of it and be blocked forever, since it has a while(true). In this scenario, the function b will never be executed not matter how much time has passed.
All this happens in libuv. The lib that backs Node.js concurrency model.
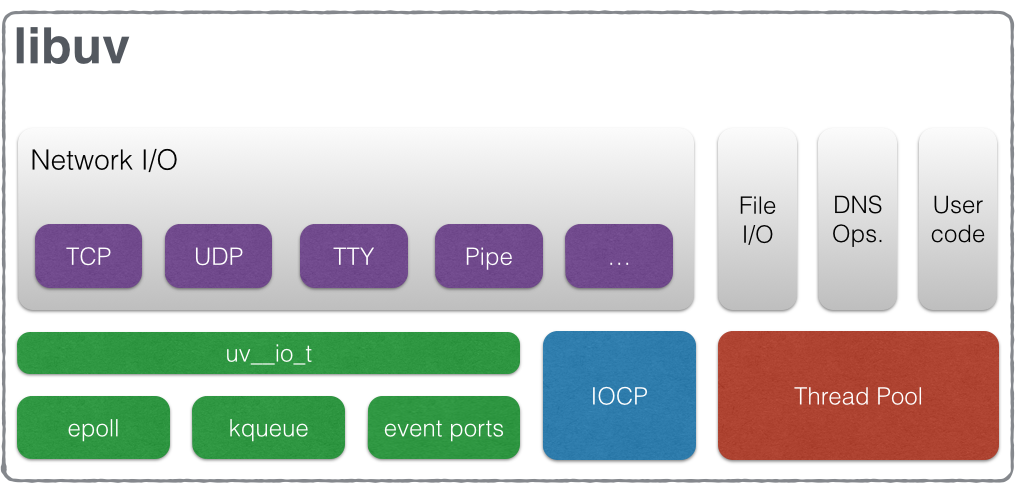
How Node.js keeps Event Loop free
Not everybody writes infinite loops like that in Node.js and when doing so they take care of it, right?
Most of our applications are I/O-bound, it means that the CPU is underused. There’s no need to have multiple threads if the most part of the job is waiting for a file descriptor/handle.
Remember: Threads consume resources
What libuv, and hence Node, does is I/O Multiplexing. This is the same thing that empowers NGINX, one of the most performative web servers out there.
Some operations still need to be done in a separate thread. Libuv, by default, uses the thread pool for file system and DNS operations. It also allows you to use the thread pool for other operations by just calling the uv_queue_work function.
In Node, some modules also leverage the threadpool, such as node:crypto and node:sqlite. The first one due to the heavy cryptographic operations and the second one due to the I/O in database operations.
The ThreadPoolWork class
Node has its constructors to empower you when dealing with other threads. One of them is the ThreadPool class. Its
definition can be found at node_internals.h.
class ThreadPoolWork {
public:
explicit inline ThreadPoolWork(Environment* env, const char* type)
: env_(env), type_(type) {
CHECK_NOT_NULL(env);
}
inline virtual ~ThreadPoolWork() = default;
inline void ScheduleWork();
inline int CancelWork();
virtual void DoThreadPoolWork() = 0;
virtual void AfterThreadPoolWork(int status) = 0;
Environment* env() const { return env_; }
private:
Environment* env_;
uv_work_t work_req_;
const char* type_;
};
The methods ScheduleWork and CancelWork are used to schedule and cancel work in the thread pool, respectively. Both implementations can be found at src/threadpoolworkd-inl.h.
As you can see, it is a wrapper around uv_queue_work and uv_cancel. This class is designed to be used in Node.js modules that need to perform work in a separate thread without blocking the main event loop.
The ThreadPoolWork class is meant to be extended by other classes that need to perform specific work in the thread pool. When doing so the DoThreadPoolWork method should be implemented to perform the actual work in the thread pool, and the AfterThreadPoolWork method should be implemented to handle the result of the work after it has been completed.
When I started working on the node:sqlite backup implementation I’ve been told to not block the event loop while the backup is happening. This is a must-have, we want to keep the event loop free to handle other requests while the backup is being performed.
SQLite runs in the same process as Node.JS. There is no networking or inter-process communication involved. We needed to have a custom implementation running in the libuv thread pool to avoid blocking the event loop.
I then used the ThreadPoolWork for that:
class BackupJob : public ThreadPoolWork {
public:
void DoThreadPoolWork() override {
backup_status_ = sqlite3_backup_step(backup_, pages_);
}
void AfterThreadPoolWork(int status) override {
int total_pages = sqlite3_backup_pagecount(backup_);
int remaining_pages = sqlite3_backup_remaining(backup_);
if (remaining_pages != 0) {
this->ScheduleWork(); // There is still work to do so we call the ScheduleWork method again
return;
}
if (backup_status_ != SQLITE_OK && backup_status_ != SQLITE_DONE) {
RejectPromiseWithError();
} else {
ResolvePromiseWithValue(total_pages);
}
}
private:
sqlite3_backup* backup_ = nullptr;
int pages_;
int backup_status_ = SQLITE_OK;
};
Of course, this is a simplified version of the actual implementation, you can check all the code in the original PR or directly in the main branch.
Notice the usage of the DoThreadPoolWork and AfterThreadPoolWork methods. The first one is where the actual work is
done, in this case, performing a backup operation using SQLite’s C API. The second one is where you can handle the
result of the work after it has been completed.
This should be called like this:
BackupJob* job = new BackupJob(); // constructor parameters are omitted for simplicity
job->ScheduleWork(); // Remember that ScheduleWork is a wrapper around uv_queue_work, as mentioned before
That’s it. Whenever you need to perform work in the thread pool, the ThreadPoolWork is an option to consider.